Scaling deep goal-conditioned RL with SIGReg-ISO
Main takeaway. Applying Sketched Isotropic Gaussian Regularization (SIGReg-ISO) to the actor trunk of a deep goal-conditioned RL network reduces representation collapse at scale. Across humanoid and reacher tasks in Brax, isotropic regularization on the actor produces more stable training and higher evaluation success rates than the unregularized baseline — without adding any learned parameters.
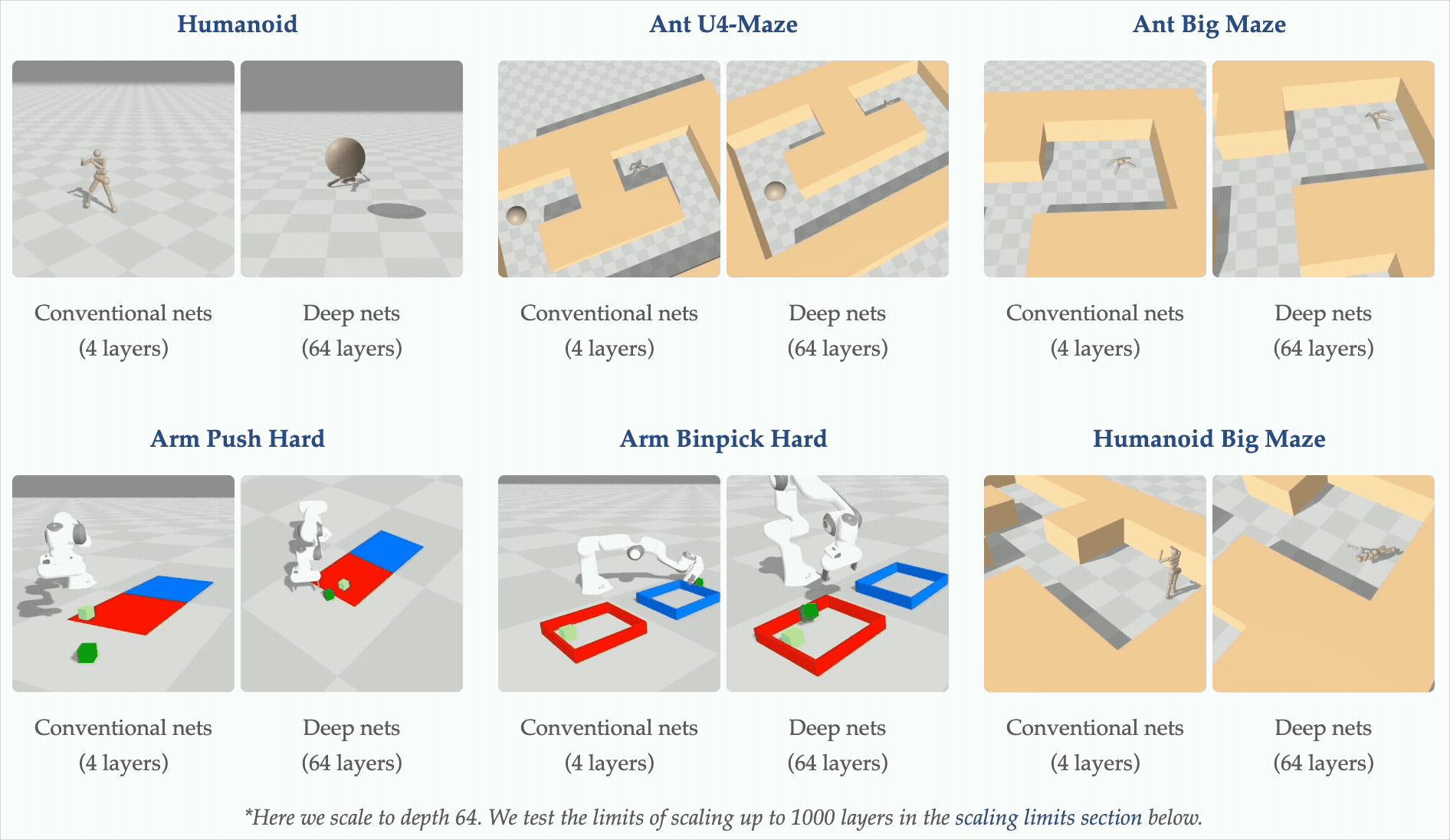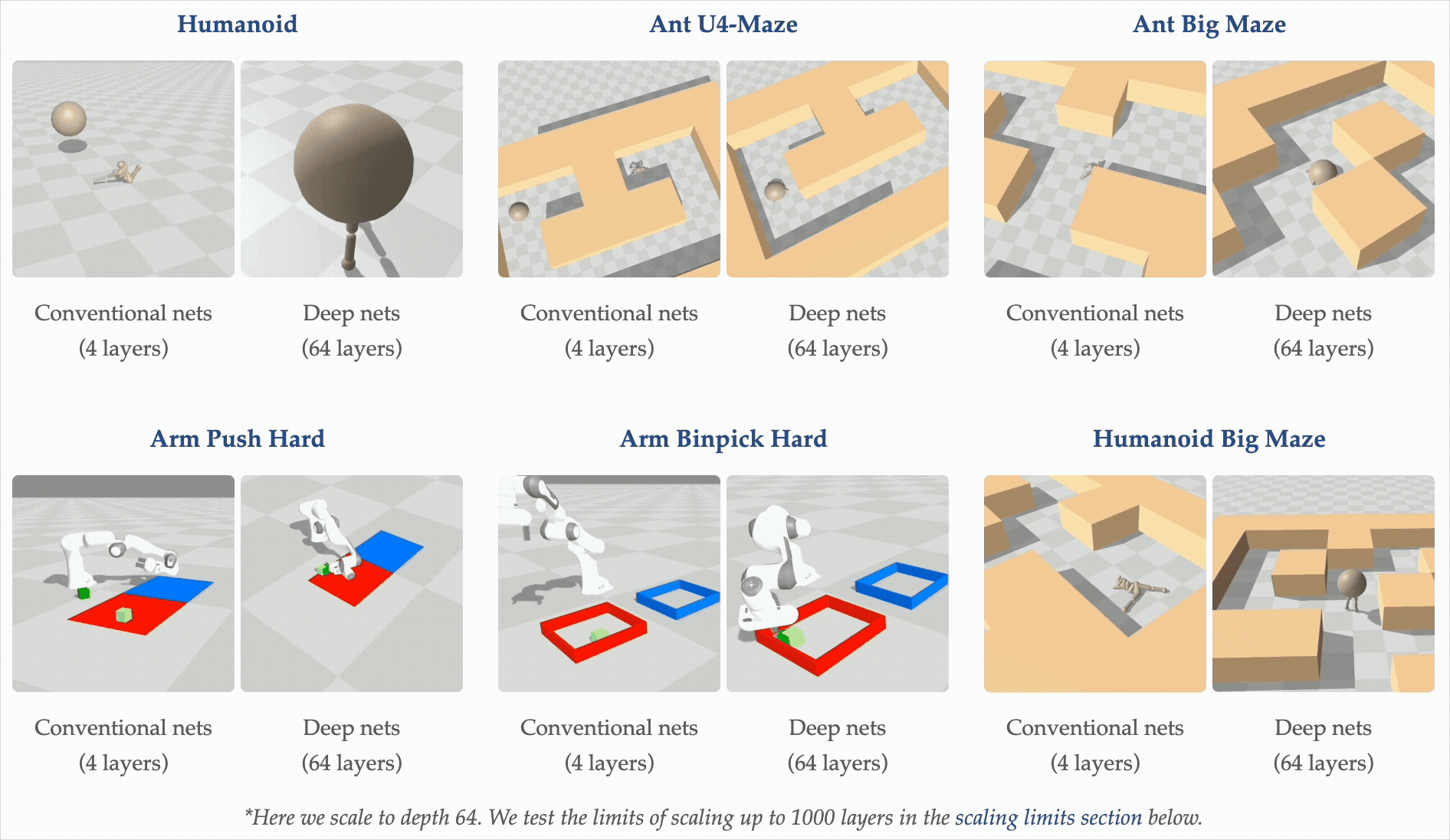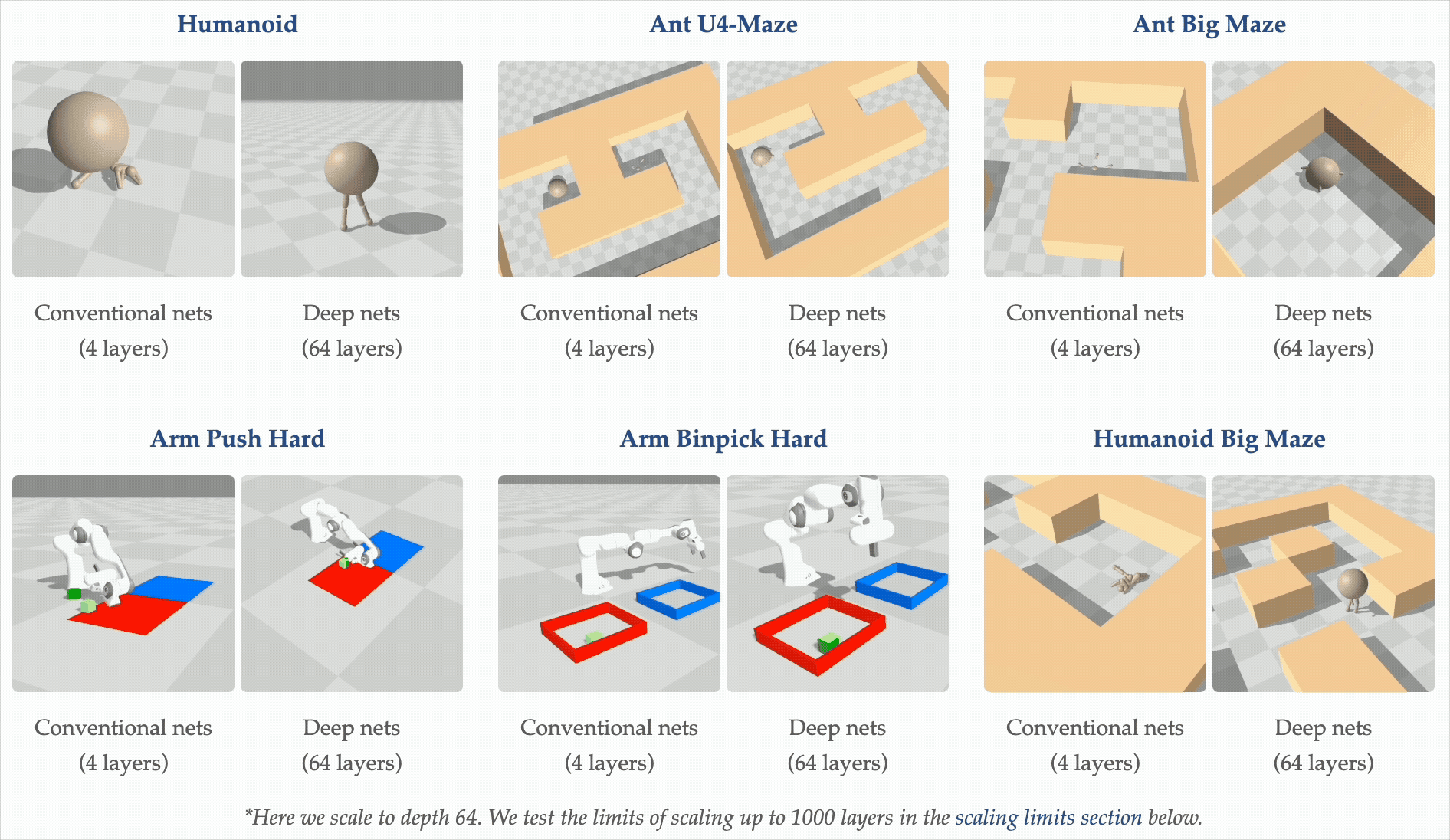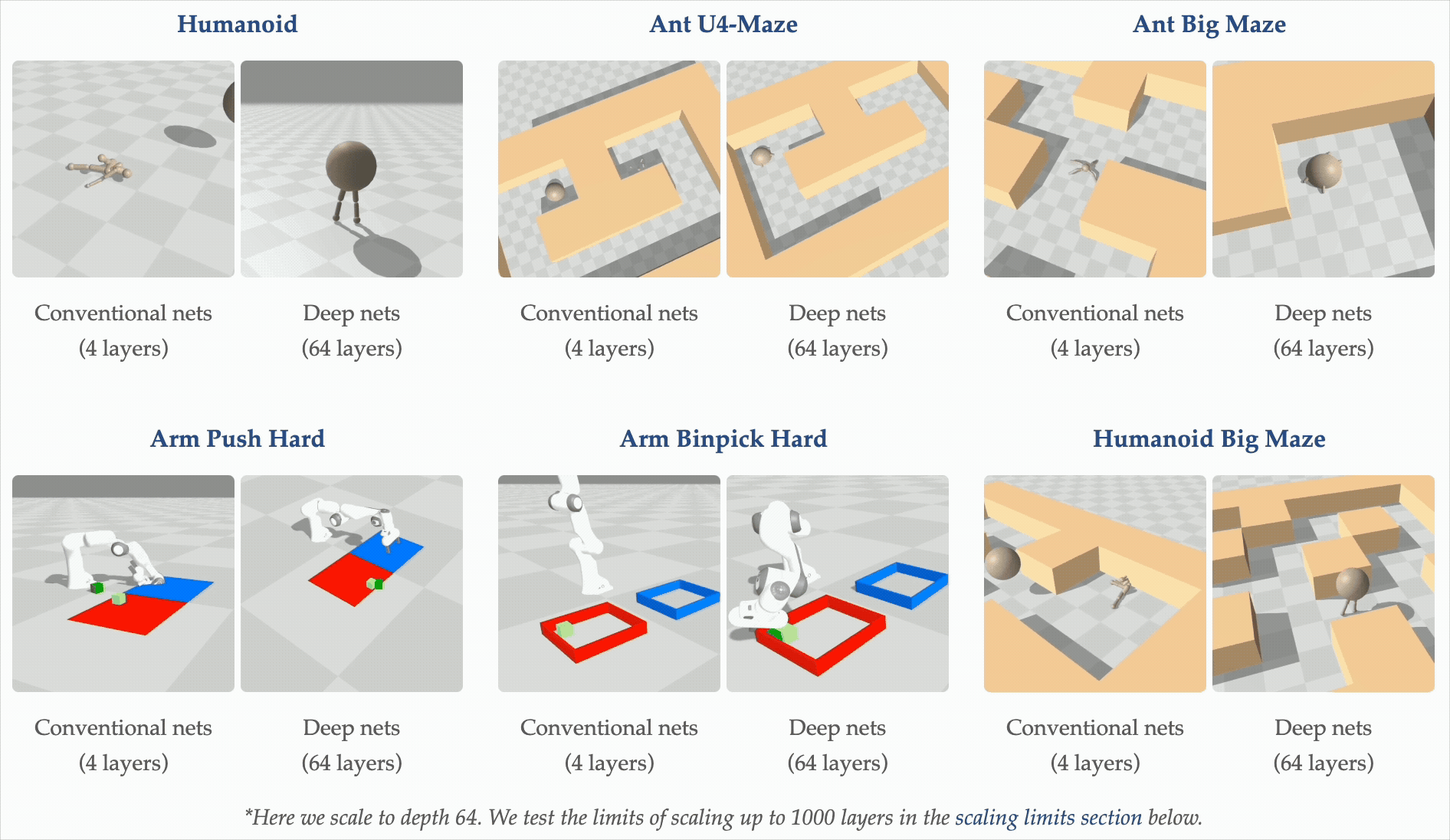
Motivation: depth scaling breaks representations
Recent work (Wang et al., NeurIPS 2025 Best Paper) shows that very deep networks — up to 1000 layers — can unlock qualitatively better self-supervised RL policies. But depth is a double-edged sword: as networks grow, representations tend to collapse into low-rank subspaces, losing the expressivity the extra capacity was supposed to provide. This project tests whether a lightweight, parameter-free regularizer can prevent that collapse specifically in the actor, leaving the critic architecture free to scale on its own terms.
What SIGReg-ISO does
SIGReg (Obando-Ceron et al., 2026) pushes a network’s intermediate representations toward an isotropic Gaussian distribution by matching sketched empirical characteristic functions to a N(0,1) reference. The “ISO” variant targets only the actor trunk. The technique requires:
- 16 random slice projections
- 8 characteristic function evaluation points
- No additional learned parameters — the loss is a distribution-matching penalty
Representation quality is tracked throughout training via effective rank, isotropy score, and participation ratio — metrics that measure how uniformly the embedding space is used, making collapse visible before it degrades policy performance.
Experiments
Three training configurations were compared head-to-head on JAX-based Brax simulations, all using the same JAXGCRL backbone:
| Configuration | Algorithm | Regularization |
|---|---|---|
| Baseline | Off-policy SAC | None |
| SIGReg-ISO (off-policy) | Off-policy SAC | ISO on actor trunk |
| SIGReg-ISO (on-policy) | On-policy PPO | ISOActor backbone |
A fourth set of runs used a frozen critic to isolate whether a high-quality critic representation alone is sufficient to bootstrap good actor learning — it isn’t, which points to the actor trunk as the critical failure mode at depth.
Results

The plots in the W&B report show that isotropic regularization on the actor trunk improves both final performance and training stability on humanoid, the hardest environment tested. On reacher tasks the gap narrows — consistent with the hypothesis that the regularizer is most important when the policy network is deepest and representations are most at risk of collapse.
Rollout comparisons
Reading the W&B report
The linked Weights & Biases report contains the full sweep: per-run curves for evaluation success rate, effective rank, isotropy score, and participation ratio across all configurations and seeds. Use it for exact hyperparameters and raw data; use this page as the summary you can share quickly with collaborators.
References
- Wang et al. — 1000 Layer Networks for Self-Supervised RL, NeurIPS 2025 Best Paper. OpenReview
- Obando-Ceron et al. — Stable Deep Reinforcement Learning via Isotropic Gaussian Representations, 2026. arXiv:2602.19373
- Bortkiewicz et al. — JAXGCRL. GitHub
- Wang et al. — Scaling CRL. GitHub