LeDEEP: monocular depth estimation with LeJEPA and SIGReg in production
Main takeaway. LeDEEP is “monocular depth estimation using a Vision Transformer encoder with LeJEPA-style multi-view self-supervised learning and SIGReg regularization.” Trained on 1280×720 aerial drone footage from the DDOS dataset, the model is served through a Flask + Gunicorn REST API with a live frontend — turning depth estimation from a research script into an endpoint any application can hit.
Why JEPA for depth estimation
Depth estimation from a single image is an ill-posed problem: without geometric cues, a model must learn rich scene priors from data. Standard supervised approaches learn only what the depth label directly supervises — they can miss relational structure between image regions that would make predictions more coherent across scale changes or viewpoint shifts.
The LeJEPA objective addresses this by adding multi-view self-supervised learning on top of depth supervision. As the README describes, the --deeplearning training mode “adds LeJEPA multi-view self-supervised learning on top of depth supervision. Each training image is augmented into 2 global crops (224px) and 4 local crops (96px), and the model learns to produce consistent representations across all of them.” This view-invariant representation pressure encourages the encoder to discover structure that correlates with depth rather than surface texture — without requiring any additional labeled data.
SIGReg is applied on top to keep those representations healthy. It prevents collapse by encouraging the embedding space to follow a standard Gaussian distribution — the same technique applied to RL actor trunks in the SIGReg-ISO project, here transferred to the vision encoder.
Architecture
The encoder is a pretrained ViT-Small (patch size 16, ImageNet-21k). It produces:
- Patch tokens — a 14×14 spatial grid fed to a progressive convolutional decoder for dense depth prediction
- CLS token — projected into a 512-dim embedding space for the JEPA objective
“The decoder upsamples through 4 stages of transposed convolutions (14×14 → 224×224) to produce a single-channel depth map normalized to [0, 1].”
The training loss is a composite: depth_weight × ScaleInvariantLoss + jepa_weight × LeJEPA_Loss. Scale-invariant loss handles the inherent depth scale ambiguity in monocular estimation; LeJEPA loss enforces cross-view consistency in embedding space.
Four modeling tiers, one codebase
The project implements a full model ladder — useful for ablation and for deploying the right model given inference constraints:
| Approach | Command | Description |
|---|---|---|
| Naive baseline | uv run train --naive | Predicts the mean training depth for every pixel |
| Classical ML | uv run train --classic | Random forest on hand-crafted patch features |
| Supervised DL | uv run train --supervised | Single-view depth supervision with SIGReg (ViT or ResNet) |
| LeJEPA DL | uv run train --deeplearning | Multi-view self-supervised learning + depth supervision (ViT) |
The supervised model is “a good starting point or ablation baseline.” The LeJEPA model is “slower to train but encourages richer, view-invariant features.”
Results
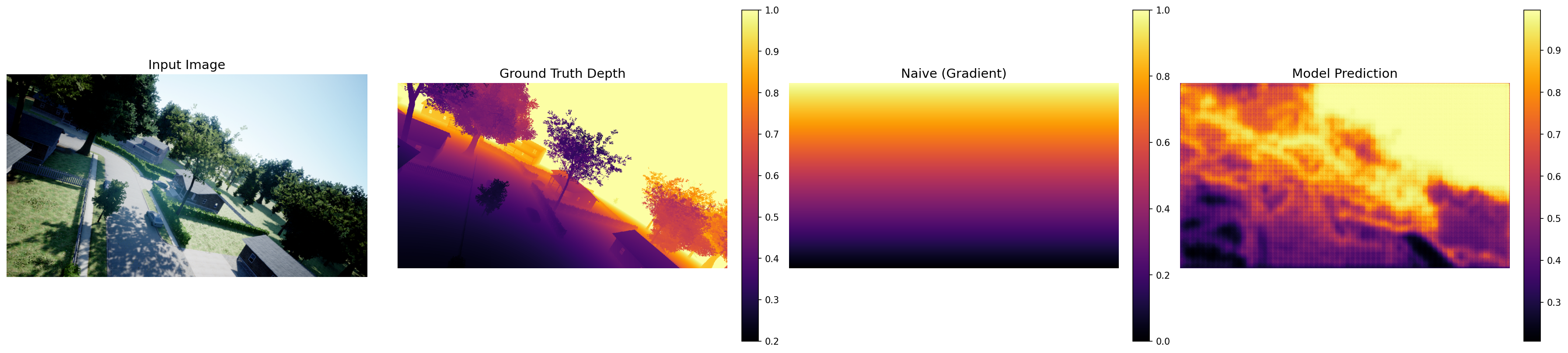
The evaluation script “runs a ViT model over the entire test split, computes pixel-level metrics (AbsRel, RMSE), and compares against a naive gradient baseline.” Per-image outputs are saved to test_results/ for qualitative inspection alongside the quantitative metrics.
Production inference server
The part that moves this beyond a notebook: “A Flask + Gunicorn server exposes the models as a REST API for the web frontend.”
Sending an image is one POST:
POST /predict-depth
Content-Type: multipart/form-data
image=<file>
model=deeplearning # optional; auto-selects best available
The response is JSON with a data URI ready to drop into an <img> tag:
{
"depth_map": "data:image/png;base64,...",
"model": "deeplearning",
"width": 1280,
"height": 720,
"inference_time_s": 0.842
}
The server “binds to 0.0.0.0:8000 by default. CORS is configured for https://aipi540-frontend.vercel.app.” In production it runs under Gunicorn with 1 worker and 4 threads — tuned to keep a single model loaded in memory while handling concurrent requests without GPU contention.
Inference on arbitrary-size images works by chunking: the ViT model “chunks into overlapping 224px patches, stitches back” — so the 224px training resolution is not a hard constraint on what you can send to the API at runtime.
Dataset
DDOS (Drone Depth and Obstacle Segmentation) — aerial RGB + 16-bit depth pairs at 1280×720, automatically downloaded via uv run setup (~136 GB, 95/5 train/val split). Depth is normalized to [0, 1] via depth / 65535.0. The aerial setting makes depth estimation harder than street-level benchmarks: dramatic scale variation, thin objects (tree branches), and irregular ground planes — all cases where view-invariant JEPA representations help most.
References
- Balestriero et al. — LeJEPA: SIGReg for Self-Supervised Learning, 2025
- Assran et al. — I-JEPA: Joint Embedding Predictive Architecture, 2023
- Eigen et al. — Scale-Invariant Loss for Depth Prediction, 2014
- benediktkol — DDOS dataset, HuggingFace